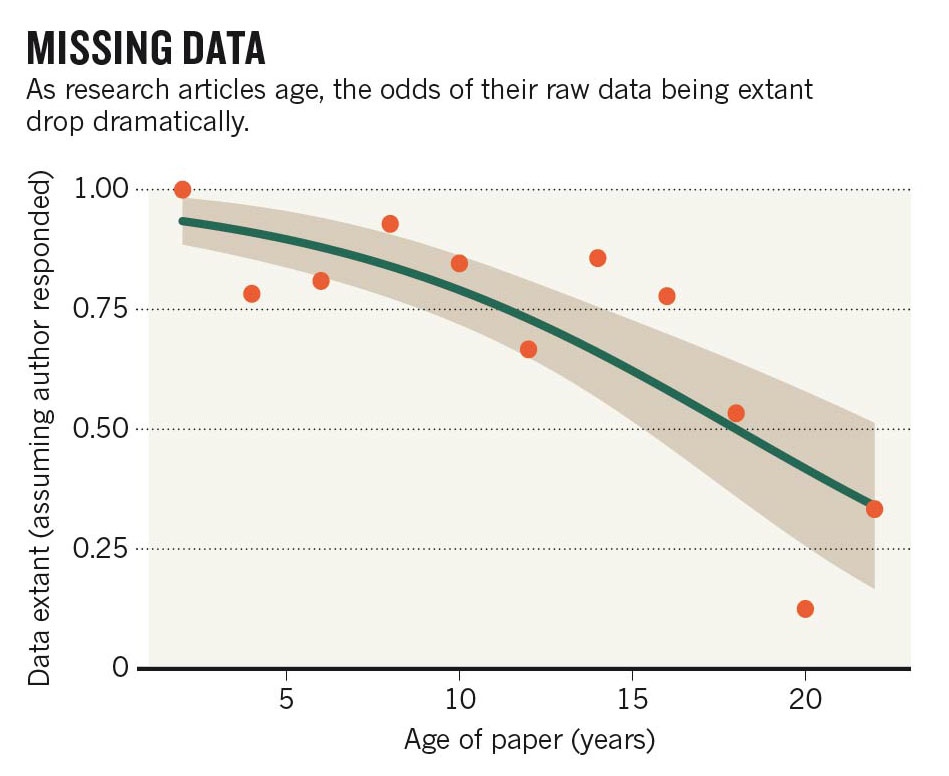
Data managers talk a lot about doing data management before your project starts, but there is another important point in a project that is critical to data management: when a project ends. My recent post on managing thesis data got me thinking about this critical project point, along with a recent tweet from Robin Rice, Data Librarian at the University of Edinburgh, on what usually happens to data post-thesis:
RDM Awareness session in GeoSciences. Q: What happens to my code and data after I write my PhD thesis? A: "The default is it gets lost!"
— Robin Rice (@sparrowbarley) December 10, 2013
While all project data are susceptible to such loss, thesis data are particularly fragile because data are often handed off to a PI when the student leaves the university. This puts someone who does not have much knowledge of the data in charge of caring for the data in the long term. The truth is that your PI will be much happier, and you will be happier with your own access in the long term, if you prep your data a bit before this hand off.
You have a distinctive opportunity to care for your data at the time when you are wrapping up a project. Not only is the data still fresh in your mind, but you probably already perform some management actions, like backing up your data and storing your notebook, when wrapping up a project. Adding a few simple steps to this process will let you enjoy the products of your work well after you finish the actual project.
Back Up Your Written Notes
People always think to back up their digital data (which you should definitely do) but few ever remember to back up written notes. This is a shame because data without the corresponding notes are often unusable. Not only does a backup copy address the possibility of a lost notebook, but it also helps the dissertators who hand over their notes at the end of their degree. If those researchers want access to their written notes after they leave their university, they must make a copy for themselves before the handover.
You can back up your notes by making physical photocopies, but any more I recommend digital scans. The benefit of scans is that you can store them directly alongside your digital data, which saves you from having to track down stray notes later. It does take time to scan a notebook, but the reward is ensuring access to your notes and maintaining the usefulness of data going forward.
Convert to Open File Formats
This is the one that has defeated me personally. Even though I have all my files from graduate school, most of my data is locked up in a proprietary format that I no longer have software to open. Don’t get stuck in the trap where you have your data but cannot read or use them!
If you haven’t done so already, wrapping up a project is a great time to convert files to an open format. Look for formats that are open, standardized, well-documented, and in wide use, such as: .csv, .tiff, .txt, .dbf, and .pdf. These formats can be opened by many programs, meaning lots of options for getting back your data when you need them.
If there isn’t a good open format for your data type, or you will lose important information during conversion, you’ll want to plan on how you’ll maintain access to the necessary software into the future. Realize that this option takes much more effort, so opt for open file format if you at all can.
Utilize “README.txt” Files
I cannot recommend “README.txt” files enough for making sense of digital files and file organization. These simple text files answer the very important questions of “What the heck am I looking at?” and “Where do I find X?” in your project file folders. This information is useful at every level of your project, from the main project folder on down to the folder containing sets of data. Plan to create one README.txt file per folder in as many folders as you can.
By their name alone, README.txt files announce that they are the first file to open when you or someone else is looking through your old data. Their job is to provide a map for exploring your files. For example, a top-level README.txt should give the general project information and a very coarse overview of file contents and locations. A low-level README.txt would be more specific as to what each file contains. These files need not be large, but their contents should provide a framework for easy navigation through your digital files and folders.
When wrapping up a project, you should create a README.txt file for at least your top-level folder and your most important project folders. This is doubly important if you are handing off your data for someone else to maintain, as good README’s make it exponentially easier for someone unfamiliar with the data figure out what’s what. Still, this system is useful to you, the data creator, in the event you come back to the data in the future.
Keep Everything Together
Finally, you will want to track down stray files and folders when you wrap up a project. It is much easier to manage all of your data if it is in one place (or two places if you have both physical and digital collections). Note that this does not include backups, which are separate and can exist offsite. Don’t forget to include things like reference libraries and relevant paper drafts in this pile; you want to save everything related to the project in the same place.
Once you have everything together, save it to an appropriate place and back it up. Keep track of your files and backups and move everything to new media every few years or so. You don’t want to be that researcher looking for Zip disk readers in 5 years. Remember that just because your project is complete, doesn’t mean that you can now ignore your data.
Final Thoughts
Researchers are often anxious to move onto the next thing when wrapping up a project, but you must resist the temptation to speed through the data preparation process. Taking an extra day to prepare your data properly can mean the difference between being able to use your data in 3 years and not having access to it at all. Between all of the time and effort you have invested in that data, and possibility that you may need it again in the future, it is worth taking a few extra steps to wrap up a project properly.